Low Rank Adaptation (LoRA) is very often used to efficiently finetune a base model for deployment across different tasks. This results in a huge collection of LoRA adapters from a single base model. One major use case for this can be seen in recommender systems. For example, say you train a foundation model for user modeling and you want to use this for different segments of users. The most straightforward solution is to train an adapter for each cohort of users. This will result in thousands of adapters and efficient serving becomes critical in that case.
S-LoRA paper solves the problem of efficient serving when you have thousands of adapters from the same base model.
TLDR and Contributions
This paper presents a system for the scalable serving of many task-specific fine-tuned LoRA adapters. It stores all the adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. It proposes, 1.) Unified Paging to efficiently use GPU memory and reduce fragmentation and 2.) a new tensor parallelism strategy (S-LoRA TP) and optimised custom CUDA kernel for heterogeneous batching of LoRA computation. Contributions can be summarised as below:
- Heterogeneous Batching and Scheduling: Introduces optimised CUDA kernels to operate directly on non-contiguous memory, in order to batch different adapters of varying rank.
- Unified Paging: Introduces unified memory pool to reduce memory fragmentation and increase batch size. The pool manages dynamic adaptor weights and KV cache tensors by unified paging mechanism.
- S-LoRA TP: Introduces a new tensor parallel strategy across multiple GPUs, to ensure that it incurs minimal communication cost for added LoRA communication compared to base model.
Preliminary
Here, I would assume that you are aware of LoRA so I won't go in too much detail. LoRA is a parameter-efficient fine-tuning method designed to adapt pre-trained large language models to new task. The motivation behind LoRA comes from the low intrinsic dimensionality of model update during adaptation (another interesting paper). In the training phase LoRA freezes the weight of pre-trained base model and adds trainable low-rank matrices to each layer.
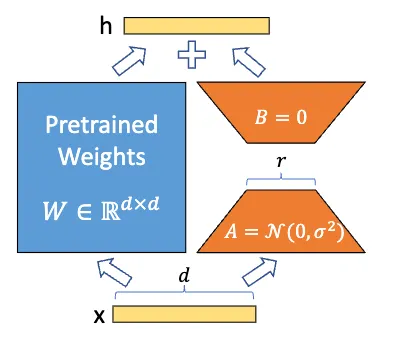
Figure 1: Reparametrization of the LoRA. Only A and B are trained and the weight of pre-trained base model W is kept frozen.(source)
Formally, for a pre-trained weight matrix W₀ ∈ ℝh × d, LoRA introduces a low-rank update ∆W = AB, where A ∈ ℝh × r, B ∈ ℝr × d, and the rank r ≪ min(h, d) and hence the update become W = W₀ + ∆W = W₀ + AB. If the forward pass of a base model is defined by h = xW₀, then after applying LoRA, the forward pass becomes:
Typically, this adjustment is only applied to the query, key, value, and output projection matrices in the self-attention module, and excludes the feed-forward module.
Heterogeneous Batching and Scheduling
The Batching Challenge
The paper's batching strategy enables online high-throughput serving of multiple LoRA adapters simultaneously. The original LoRA paper suggests to merge the weight into the base model (equation 1). This leads to no additional overhead during the inference since the resulting model has the same parameters count as the base models.
However, when serving multiple adapters this creates problems of multiple weight copy of the same model, consuming excessive memory. While the LoRA paper propose adding and subtracting adapter weights on-the-fly to avoid memory overhead, this approach doesn't support concurrent inference on separate LoRA adapters and therefore limiting batching opportunities.
S-LoRA's Solution
S-LoRA proposes LoRA computation xAB on-the-fly (equation 2) rather than merging weight. This eliminates duplication and enables batching of the more costly xW₀ operation. While this adds an additional overhead of xAB computation, this computation is substantially lower than xW₀ and the savings from batching the base model computation more than compensate for it.

Figure 2: Separated batched computation for the base model and LoRA computation. The batched computation of the base model is implemented by GEMM. The batched computation for LoRA adapters is implemented by custom CUDA kernels which support batching various sequence lengths and adapter ranks. (source)
Custom CUDA Kernels
Directly implementing the factored computation of the base model and individual LoRA adapters using the batch GEMM kernel from the existing BLAS libraries would require significant padding due to the heterogeneity of sequence lengths and adapter ranks resulting in poor hardware utilization.
Instead, S-LoRA batches the computation of the base model xW₀ and then uses custom CUDA kernels to efficiently compute xAB for each adapter separately without padding (see Figure 2). This custom implementation achieves much better performance than naive batched approaches.
Memory Management Strategy
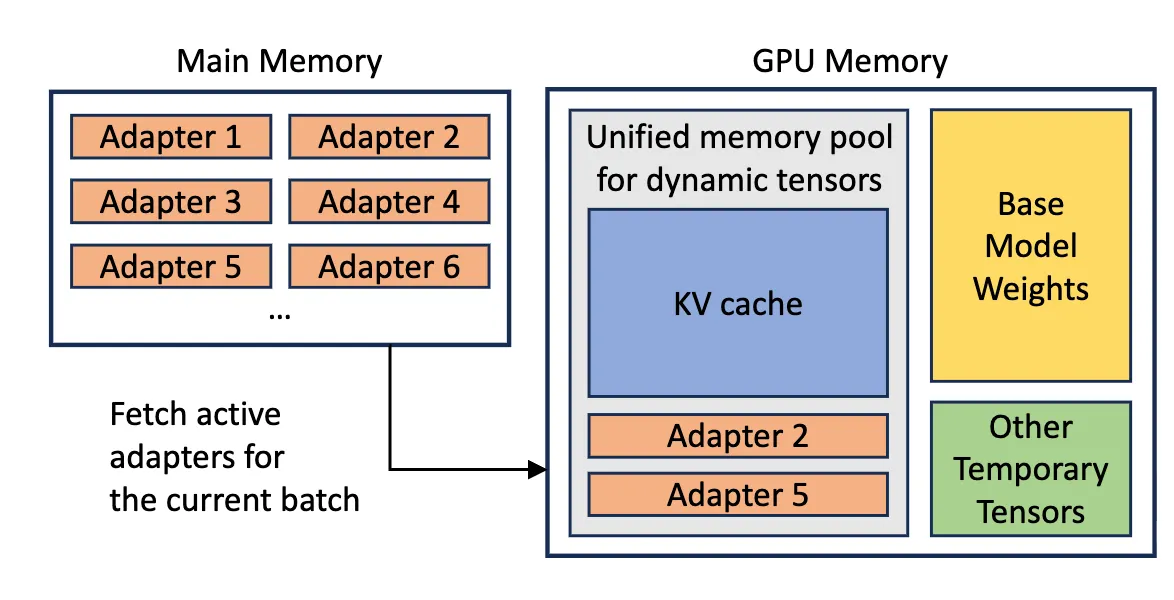
Figure 3: Overview of memory allocation in S-LoRA. S-LoRA stores all adapters in the main memory and fetches the active adapters for the current batch to the GPU memory. The GPU memory is used to store the KV cache, adapter weights, base model weights, and other temporary tensors (source).
While the total number of LoRA adapters can be large, only a subset is needed for any given batch, and the batch size itself is constrained by GPU memory. S-LoRA exploits this by storing all adapters in main memory (RAM) and dynamically loading only the adapters required for the current batch onto the GPU. This means the system's adapter capacity is bounded by main memory rather than GPU memory, enabling it to serve thousands of adapters.
Token-Level Scheduling
To maximize throughput, S-LoRA adopts iteration-level scheduling from Orca, where requests are scheduled at the token level rather than the sequence level. New requests are immediately added to the running batch whenever space becomes available, and requests exit the batch once they complete generation or meet stopping criteria. This approach significantly reduces GPU memory usage compared to traditional batching, but introduces new memory management challenges that we will discuss later.
Adapter Clustering
To further improve batching efficiency, S-LoRA can reduce the number of active adapters in a running batch. With fewer adapters consuming memory, more space becomes available for the KV cache, enabling larger batch sizes. Since GPUs are often underutilized during the decoding phase, increasing batch size directly translates to higher throughput. A straightforward way to reduce active adapters is through "adapter clustering", prioritizing requests that use the same adapter when forming batches. However, this comes with trade-offs: it can increase average latency and create fairness issues, as some adapters may be prioritized over others.
Admission Control
When traffic exceeds system capacity, S-LoRA employs admission control to maintain service quality. Serving systems typically operate under a service level objective (SLO) that specifies target latency. Without admission control, an overloaded system will eventually violate its SLO for all requests as the queue grows unbounded. S-LoRA implements an "early abort" strategy: it estimates which recent requests can be served within the SLO and processes them in arrival order, dropping requests that cannot meet the latency requirement. This ensures the system maintains its SLO for accepted requests even under high load.
Unified Paging and Memory Management
Serving multiple LoRA adapters introduces unique memory challenges. S-LoRA stores adapters in main memory (RAM) and dynamically loads them to GPU RAM as needed. This creates two key problems:
- Memory fragmentation from loading and unloading adapters of varying sizes
- I/O latency overhead when transferring adapters between main memory and GPU
S-LoRA addresses these through Unified Paging and intelligent prefetching.
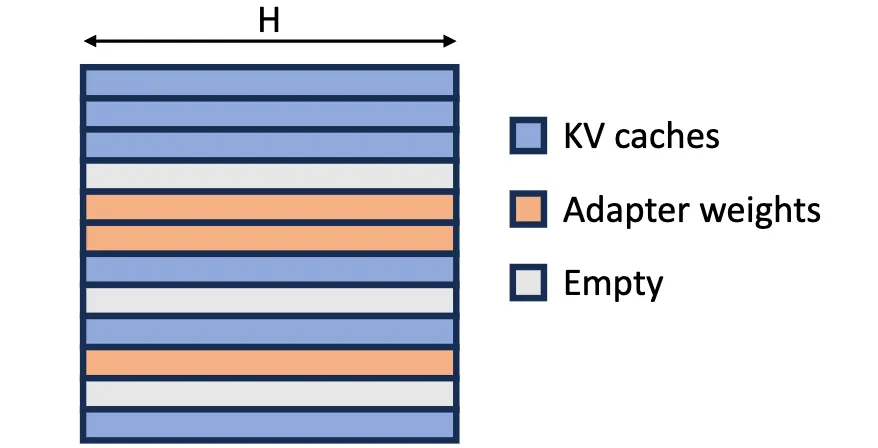
Figure 4: Unified memory pool. We use a unified memory pool to store both KV caches and adapter weights in a non-contiguous way to reduce memory fragmentation. The page size is H elements.
Unified Paging
The key observation: adapter weights behave similarly to KV caches.
Similarities between adapter weights and KV caches:
- Variable sizes: KV cache size varies with sequence length; adapter sizes vary with rank. Both are allocated on request arrival and deallocated on completion, leading to fragmentation if mismanaged.
- Shared dimensionality: KV cache tensors have shape (S, H) where S is sequence length and H is hidden dimension. LoRA weights have shape (R, H) where R is rank. Both share the H dimension, which we can exploit.
Inspired by PagedAttention, S-LoRA introduces Unified Paging, a single memory pool managing both KV caches and adapter weights.
Algorithm
- Allocate a large static buffer using all available space (excluding base model weights and temporary activations)
- Store both KV caches and adapter weights in pages of size H
- A KV cache with sequence length S uses S pages; a LoRA weight with rank R uses R pages
- KV caches and adapter weights are stored interleaved and non-contiguously (Figure 4)
This reduces fragmentation, allowing adapters of various ranks to coexist with dynamic KV caches efficiently.
Prefetching and Overlapping
While Unified Paging solves fragmentation, I/O overhead remains, especially with many or large adapters. S-LoRA addresses this through dynamic prediction.
- While processing the current batch, predict which adapters are needed next based on the waiting queue.
- Prefetch and load predicted adapters into available memory.
- By the time the next batch runs, most required adapters are already loaded, minimizing I/O latency
Custom CUDA Kernels
The non-contiguous memory layout requires specialized computation kernels. S-LoRA implements custom CUDA kernels that efficiently handle heterogeneous LoRA batching across varying ranks and sequence lengths:
Prefill stage (processing sequences): At this stage kernel handles a sequence of tokens and gathers adapter weight with different rank from the memory pool. This kernel is called MBGMM (Multi-size Batched Gather Matrix-Matrix Multiplication) kernel.
Decode stage (processing single tokens): At this stage the kernel handles a single token and gather adapter weights with different rank from the memory pool. It is called MBGMV (Multi-size Batched Gather Matrix-Vector Multiplication) kernel. The paper tested two implementations: Triton and modified Punica kernels. Modified Punica version was faster, supporting non-contiguous memory, multiple ranks per batch, and fine-grained memory gathering
S-LoRA Tensor Parallelism
To support multi-GPU inference of large transformer models with batched LoRA adapters, S-LoRA introduces novel tensor parallelism strategies. Tensor parallelism is the most widely used parallelism method due to its single-program multiple-data (SPMD) pattern, which simplifies implementation and integration. It reduces per-GPU memory usage and latency when serving large models. However, LoRA adapters introduce new weight matrices and matrix multiplications that require careful partitioning strategies.
Partition Strategy
The base model uses the Megatron-LM tensor parallelism strategy, so S-LoRA's approach aligns the partition strategies of the added LoRA computation with those of the base model. This alignment minimizes communication costs by avoiding unnecessary data transfers and enabling communication fusion.
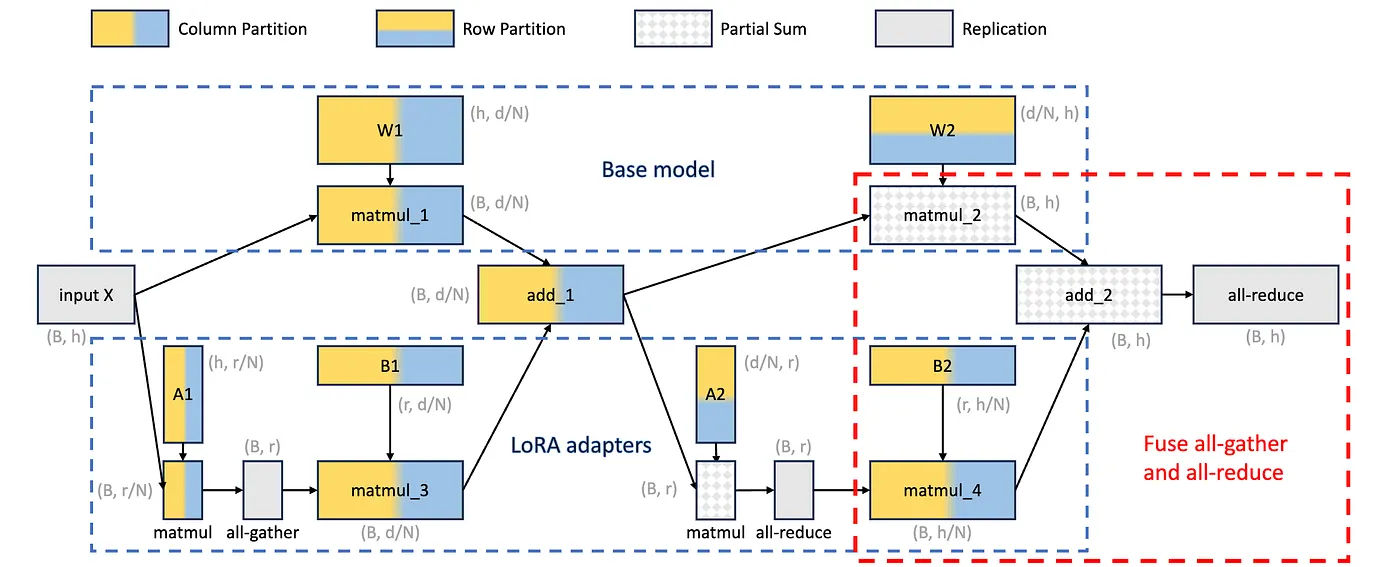
Figure 5: Tensor parallelism partition strategy for batched LoRA computation. This is a computational graph where nodes represent tensors/operators and the edges represent dependency. We use different colors to represent different partition strategies, which include column partition, row partition, partial sum, and replication. The per-GPU shape of each tensor is also annotated in gray. Note that B is the number of tokens, h is the input dimension, N is the number of devices, d is the hidden size, and r is the adapter rank (source).
Base Model Partitioning (Megatron-LM):
Let's examine the feed-forward module (2-layer MLP) shown in Figure 5:
- First weight matrix (W₁): column-partitioned
- Second weight matrix (W₂): row-partitioned
- Final step: all-reduce operation to accumulate partial sums
LoRA Adapter Partitioning:
For adapters on W₁ (matrices A₁ and B₁):
- Both A₁ and B₁: column-partitioned
- Intermediate results: collected via all-gather operation
For adapters on W₂ (matrices A₂ and B₂):
- A₂: row-partitioned
- B₂: column-partitioned
- Intermediate results: summed via all-reduce operation
Optimization: The all-reduce for LoRA computation is fused with the base model's final all-reduce. Instead of two separate all-reduce calls, S-LoRA performs just one, essentially fusing an all-gather operation for the final LoRA matrix multiplication with the base model's reduction.
Extension to self-attention layers: The strategy adapts naturally by partitioning along the head dimension (following Megatron-LM):
- Query-key-value projection weight matrix → treated as W₁
- Output projection weight matrix → treated as W₂
Communication and Memory Analysis
Given N devices, B tokens, hidden size h, and adapter rank r:
- Base model: One all-reduce = $2(N-1)Bh/N$
- LoRA computation: Three all-gather (Q, K, V) + one all-reduce (output) = $5(N-1)Br/N$
Why this is efficient: Since $r \ll h$ (adapter rank is much smaller than hidden size), the additional communication cost from LoRA is negligible. This is achieved by:
- Carefully scheduling communications on small intermediate LoRA tensors
- Fusing LoRA operations with base model communications
Memory usage: This strategy is optimal, all weight matrices are partitioned across devices with zero replication, maximizing memory efficiency.
Reference
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters
- LoRA: Low-Rank Adaptation of Large Language Models
- Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
- ORCA: A Distributed Serving System for Transformer-Based Generative Models
- Efficient Memory Management for Large Language Model Serving with PagedAttention