This is the first part of the blogpost series about the tokenization in Language Models.
If you have seen Karpathy Sensei's video[1], you must be aware of the fact that tokenizer is one of the most "problematically important" concept in NLP. The video is probably the best explanation available on internet for understanding tokenization. Tokens are the most fundamental unit of large language models. LLMs don't see the word like we do but they are fed these words in different way, called 'tokens'. Different tokenization methods are used in different open and closed source large language models.
Figure below shows the rough high level block diagram of a language model depicting tokenization in it:
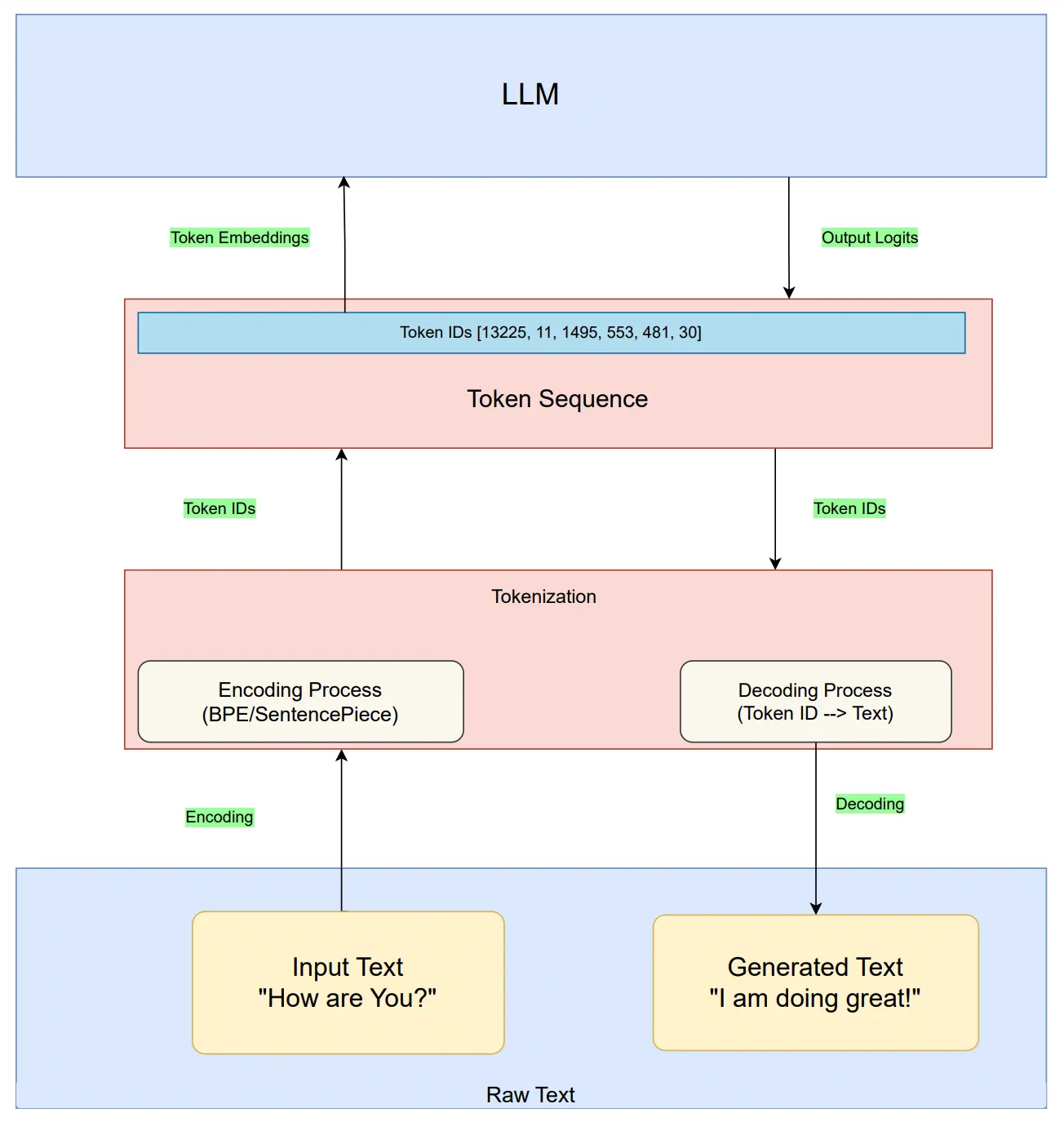
Figure 1: A high level rough block diagram of a language model depicting tokenization. Note that output logits will have probability score over entire vocabulary, not for input token. Note than tokenizer is a separate module and it has their own training data. LLMs only sees the tokens and never directly deals with the texts.
Tokenization
Tokenization is the process of converting texts data into token :') . Tokens are the most fundamental unit of large language models. When we use large language models, it first converts our input texts/images/videos into some fundamental unit that we call tokens. The process of this conversion from input texts to token is called tokenization. When you write on ChatGPT, "write an ode on the end of universe.", it first converts your input into this format:
Which is then converted to the following numerical sequence:
You can use this website (https://tiktokenizer.vercel.app/) to play with different input text. In this blog we will learn how does this convert from text sequence to numerical sequence happens.
There are several methods, one of the most basic one is to use it in same way that a python code process the string, in the raw byte form. Just use "utf-8" encoding of the input and then we are done. But, we don't!!! Why not we just use "utf-8" encoding?
- The vocabulary size is will be fixed (256 unique byte values). Isn't that a good thing??
- This will allow us to have smaller input embedding table and prediction at the final layer. Another good thing??
- It will require modeling all possible byte combinations for meaningful language patterns and make our input sequences very very long.
- Because of this reason, transformer input layer will need to process much longer input context, which is not computationally efficient for attention based models. Remember??, OpenAI charges you based on no of input tokens if we use 'utf-8', our api cost will become much much larger.
- Also, 'utf-8' does not have any semantic understanding. For example it treats the word "unhappiness" as 11 completely separate characters and doesn't recognize that this word contains meaningful subparts: "un-" (prefix), "happy" (root), "-ness" (suffix). Model will need more data to understand semantic representation if directly use utf-8 encoding.
- Many predictions in language depend on previous words or even syntactic phrases, and focusing on individual characters/bytes is so low-level that it makes it more challenging to learn about those higher levels of abstraction[10].
For example Japanese word for Good Morning, Ohayou gozaimasu, "おはようございます", will be converted into 27 different tokens using 'utf-8' encoding:
However if we use current GPT-4o tokenizer it will just use 4 tokens:
This provides almost 7x compression in the input token size.
Therefore, we need to find some other way to encode our data which is more efficient than simple byte encoding like 'utf-8'. Then, why don't we use each word as a separate token???
If we use word based tokenizations, it is practically impossible to create a dictionary of all the words in human history. Hence, word level tokenization will almost always have out of vocabulary problems and multi-linguality might become a distant dream for those types of model. Whenever we come up with new words and use that word to ask something from our model, it will throw an error.
One set of method to solve both of these problems is called subword based tokenization which is being used in all the modern language models. Subword based tokenization solves both of these problems by allowing words to be decomposed into subwords and bringing the best of these world. Byte Pair Encoding is one of the example of subword based tokenization.
Byte Pair Encoding
BPE is one of the most common subword based tokenization. It works by replacing the highest-frequency pair of bytes with a new byte that was not there in the initial vocabulary. By design, it keeps more frequent words intact in the vocabulary and breaks down less frequent words. Let's understand this with an example from the Wikipedia article:
Initial Setup:
Data: aaabdaaabac
Characters: {a, b, c, d}
Pairs of bytes: [aa, aa, ab, bd, da, aa, aa, ab, ba, ac]
"aa" occurs 4 times (most frequent)
Replace "aa" with "Z" → Result: ZabdZabac
Updated vocabulary: {"aa", "a", "b", "c", "d"}
Updated pairs: [Za, ab, bd, dZ, Za, ab, ba, ac]
"ab" occurs 2 times
Replace "ab" with "Y" → Result: ZYdZYac
Updated vocabulary: {"aa", "ab", "a", "b", "c", "d"}
Updated pairs: [ZY, Yd, dZ, ZY, Ya, ac]
"ZY" (which represents "aaab") occurs 2 times
Replace "ZY" with "X" → Final Result: XdXac
Final vocabulary: {"aaab", "aa", "ab", "a", "b", "c", "d"}
Insight: We can no longer create pairs with frequency > 1, so the algorithm stops.
The original string aaabdaaabac (11 characters) is now represented as XdXac (5 tokens).
Note: This example uses "byte" and "character" interchangeably for simplicity. BPE has two variants: character-level BPE and Byte-level BPE [12, 14]. Byte-level BPE converts data into byte sequences and applies the same merging logic.
text = "まいにち まいにち ぼくらはてっぱんの
うえで やかれて いやになっちゃうよ
あるあさ ぼくは みせのおじさんと
けんかして うみに にげこんだのさ
はじめて およいだ うみのそこ
とっても きもちが いいもんだ
おなかの あんこが おもいけど
うみは ひろいぜ こころがはずむ
ももいろ サンゴが てをふって
ぼくの およぎを ながめていたよ
まいにち まいにち たのしいことばかり
なんぱせんが ぼくのすみかさ
ときどき サメに いじめられるけど
そんなときゃ そうさ にげるのさ
いちにち およげば はらぺこさ
めだまも くるくる まわっちゃう
たまには エビでも くわなけりゃ
しおみず ばかりじゃ ふやけてしまう
いわばの かげから くいつけば
それは ちいさな つりばりだった
どんなに どんなに もがいても
ハリが のどから とれないよ
はまべで みしらぬ おじさんが
ぼくを つりあげ びっくりしてた
やっぱり ぼくは たいやきさ
すこし こげある たいやきさ
おじさん つばを のみこんで
ぼくを うまそうに たべたのさ"
tokens = text.encode("utf-8")
tokens = list(map(int, tokens))
print('---')
print(tokens)
print(len(token)) # 1245
# [10,227,129,190,227,129,132,227,129,171,227,129,161,32,227,...]The above code simply convert any text into "utf-8" encoding. We can now use the logic discussed above to write the code for BPE. Most of these code are from Karpathy Sensei's video and colab notebook. We used the lyrics of Japanese song 'Oyoge! Taiyaki Kun' and got a total of 1245 tokens using 'utf-8' encoding.
- Get the stats of each byte pair available in the dataset. Like we did in the wikipedia example and sort it in the reverse order of token pair counts.
def get_stats(ids: list) -> dict:
"""
Calculate frequencies of adjacent token pairs in a sequence.
Args:
ids (list): A list of token IDs to analyze.
Returns:
dict: A dictionary mapping token pairs (tuples) to their frequencies.
Example:
>>> get_stats([65, 66, 65, 66, 67])
{(65, 66): 2, (66, 65): 1, (66, 67): 1}
"""
counts = {}
# Use zip to create pairs of adjacent tokens
# ids[1:] creates a shifted copy, so zip creates adjacent pairs
for pair in zip(ids, ids[1:]):
# Increment count for this pair, defaulting to 0 if not seen before
counts[pair] = counts.get(pair, 0) + 1
return counts
stats = get_stats(tokens)
print(sorted(((v,k) for k,v in stats.items()), reverse=True))- Now, let's see the code for the merge operation. Merge operation will merge token pairs into a single new token like in the wikipedia example we replaced, 'aa' with 'Z'; 'ab' with 'Y' and "ZY" with X. It simply takes the list of all token ids (ids), and pair of tokens (pair) that we want to replace and the new token id (idx), that we want all the occurrences of the pair in token lists(ids) to replace with. It return the list of all the updated tokens.
def merge(ids: list, pair: tuple, idx: int) -> list:
"""
Merge all occurrences of a token pair into a single new token.
Args:
ids (list): List of token IDs to process.
pair (tuple): Tuple of two token IDs to merge (t1, t2).
idx (int): New token ID to assign to merged pair.
Returns:
list: New list with specified token pairs merged.
Example:
>>> merge([65, 66, 67, 65, 66], (65, 66), 256)
[256, 67, 256]
"""
newids = []
i = 0
while i < len(ids):
# Check if we've found our target pair
if (i < len(ids) - 1 and # Not at last token
ids[i] == pair[0] and # First token matches
ids[i+1] == pair[1]): # Second token matches
newids.append(idx) # Add merged token ID
i += 2 # Skip both tokens
else:
newids.append(ids[i]) # Keep current token
i += 1
return newids
# Main BPE training process
vocab_size = 350 # Target vocabulary size
num_merges = vocab_size - 256 # Number of merges needed
# 256 is typically the base vocabulary (byte tokens)
ids = list(tokens) # Create working copy of original tokens
# Dictionary to store merge rules: (token1, token2) -> new_token
merges = {}
# Perform merges until we reach desired vocabulary size
for i in range(num_merges):
# Get frequency counts of all adjacent pairs
stats = get_stats(ids)
# Find most frequent pair
pair = max(stats, key=stats.get)
# Assign new token ID (starting from 256)
idx = 256 + i
print(f"merging {pair} into a new token {idx}")
# Apply the merge throughout the token list
ids = merge(ids, pair, idx)
# Store the merge rule for later use
merges[pair] = idx# We can also calculate the compression ratio
print("tokens length:", len(tokens))
print("ids length:", len(ids))
print(f"compression ratio: {len(tokens) / len(ids):.2f}X")We observe that we got 3.25x compression in the tokens by using BPE as compared to 'utf-8'. We can actually see how increasing dictionary size / vocab size improves the compression ratio for our text data. Following figure shows it for our data:
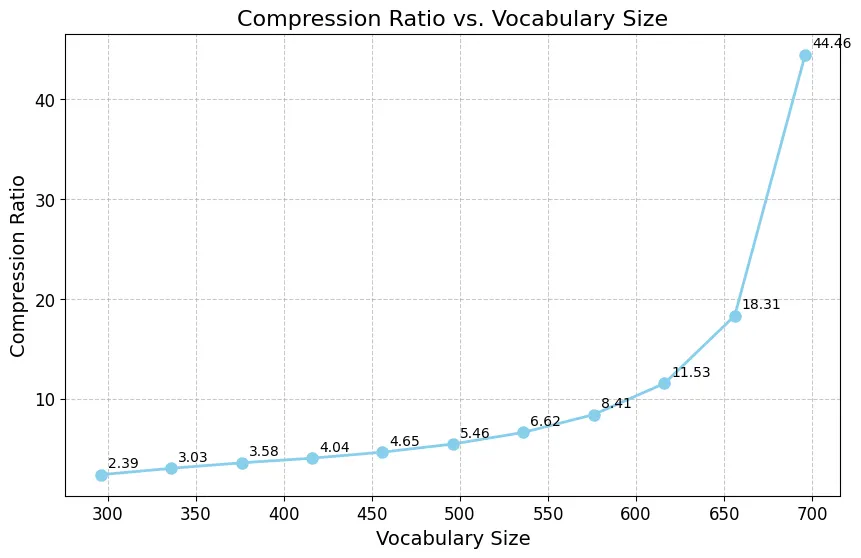
Figure 2: Vocab size vs compression ratio. We can observe that increasing vocab size increase the compression ratio, hence less no of token will be needed if we have very large vocabulary size.
As we saw in the figure 1 that tokenizers is a separate module, that deals with text to token conversion. LLM never directly sees the texts and it always deals with tokens. So after getting all these secret sauces of BPE encoding we actually need to encode a string. But remember we created all the secrete sauce based on the only limited Japanese texts, so our encoder won't be very efficient and for english words it will be same as raw 'utf-8' encoding, that is the number of tokens for the english word after encoding will be same as no of characters in the input texts. Therefore it is very important to train our tokenizers on diverse set of datasets from different languages.
def encode(text: str) -> list:
"""
Encode a text string into a sequence of token IDs using learned BPE merges.
This function:
1. Converts the input text to UTF-8 bytes
2. Iteratively applies learned merge rules to create larger tokens
3. Stops when no more merges are possible
Args:
text (str): The input text to be tokenized
Returns:
list: A list of integer token IDs
Example:
>>> encode("hello")
[256, 108, 111] # where 256 might be the merged token for 'he'
Notes:
- Uses the global 'merges' dictionary containing learned BPE merge rules
- Applies merges greedily, choosing the lowest-indexed merge rule when multiple apply
- Merge rules are applied until no further merges are possible
"""
# Convert input text to list of UTF-8 bytes
tokens = list(text.encode("utf-8"))
# Continue merging as long as we have at least 2 tokens
while len(tokens) >= 2:
# Get statistics (frequencies) of token pairs, since we need the keys of all pairs
stats = get_stats(tokens)
# Find the merge rule with lowest index
# merges.get(p, float("inf")) returns float("inf") if p isn't in merges
# This ensures pairs without merge rules are never selected
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
# If the best pair has no merge rule, we're done
if pair not in merges:
break # nothing else can be merged
# Get the new token ID for this pair
idx = merges[pair]
# Apply the merge throughout our token list
tokens = merge(tokens, pair, idx)
return tokens
encoded_tokens_eng = encode("hello world")
encoded_tokens_japanese = encode("まいにち")
print(len("hello world"), len("まいにち"))
print(len(encoded_tokens_eng), len(encoded_tokens_japanese))we can see that for english words there is no compression but for a new Japanese word "まいにち" we are seeing slight compression.
Decoding it back
Decoders converts back the sequence of encoded tokens to string. Since, we already discussed that LLMs always deal with tokens, it take in tokens and gives out tokens. Tokenizer module must be able to also convert a sequence of tokens back to strings for us human to understand.
Let's understand that by following code:
from typing import Dict, List, bytes
# Initialize vocabulary with single byte tokens
vocab: Dict[int, bytes] = {idx: bytes([idx]) for idx in range(256)}
# Extend vocabulary with merged tokens from merges dictionary
for (p0, p1), idx in merges.items():
vocab[idx] = vocab[p0] + vocab[p1] # this addition is in bytes so it will concatenate two bytes
def decode(ids: List[int]) -> str:
"""
Decodes a sequence of token IDs back into a text string using a pre-computed vocabulary.
The function performs the following steps:
1. Converts each token ID to its corresponding bytes using the vocabulary
2. Concatenates all bytes together
3. Decodes the resulting bytes into a UTF-8 string
Args:
ids (List[int]): A list of integer token IDs to decode.
Returns:
str: The decoded text string.
Global Dependencies:
- vocab (Dict[int, bytes]): A dictionary mapping token IDs to their byte sequences.
Example:
>>> decode([104, 101, 108, 108, 111])
'hello'
Notes:
- Uses 'replace' error handling for UTF-8 decoding, which replaces invalid
byte sequences with the � character rather than raising an error.
- The vocabulary is expected to be initialized with single bytes (0-255)
and extended with merged token pairs.
"""
# Convert token IDs to bytes and join them, concatenate all the bytes togather
tokens: bytes = b"".join(vocab[idx] for idx in ids)
# Decode bytes to UTF-8 string, replacing invalid sequences
text: str = tokens.decode("utf-8", errors="replace")
return text
result = decode([104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100])
print(result)
decode_eng = decode(encoded_tokens_eng)
decode_jap = decode(encoded_tokens_japanese)
print(decode_eng)
print(decode_jap)Let's wrap everything up
Now let's create a module to do everything from training the BPE tokenizer to encoding a string and decoding it back.
class BPETokenizer:
"""
Byte-Pair Encoding (BPE) Tokenizer Implementation.
This tokenizer starts with a base vocabulary of bytes (0-255) and iteratively
merges the most frequent pairs of tokens to create new tokens until the
desired vocabulary size is reached.
"""
def __init__(self, vocab_size: int = 512):
"""
Initialize the BPE tokenizer.
Args:
vocab_size (int): Target size of the vocabulary. Must be > 256.
"""
if vocab_size <= 256:
raise ValueError("Vocabulary size must be greater than 256")
self.vocab_size = vocab_size
self.vocab = None
self.merges = None
def get_stats(self, ids: list) -> dict:
"""
Calculate frequencies of adjacent token pairs in a sequence.
Args:
ids (list): List of token IDs to analyze.
Returns:
dict: Mapping of token pairs to their frequencies.
"""
counts = {}
for pair in zip(ids, ids[1:]):
counts[pair] = counts.get(pair, 0) + 1
return counts
def merge(self, ids: list, pair: tuple, idx: int) -> list:
"""
Merge all occurrences of a token pair into a single new token.
Args:
ids (list): List of token IDs to process.
pair (tuple): Tuple of two token IDs to merge (t1, t2).
idx (int): New token ID to assign to merged pair.
Returns:
list: New list with specified token pairs merged.
"""
newids = []
i = 0
while i < len(ids):
if (i < len(ids) - 1 and
ids[i] == pair[0] and
ids[i+1] == pair[1]):
newids.append(idx)
i += 2
else:
newids.append(ids[i])
i += 1
return newids
def train(self, text: str):
"""
Train the tokenizer on input text.
Args:
text (str): Input text to train on.
"""
# Initialize base vocabulary with bytes
self.vocab = {idx: bytes([idx]) for idx in range(256)}
self.merges = {}
# Convert text to bytes for initial tokens
tokens = list(text.encode("utf-8"))
ids = list(tokens) # Working copy
# Calculate number of merges needed
num_merges = self.vocab_size - 256
# Perform merges
for i in range(num_merges):
# Get pair frequencies
stats = self.get_stats(ids)
if not stats:
break # No more pairs to merge
# Find most frequent pair
pair = max(stats, key=stats.get)
idx = 256 + i
# Perform merge
ids = self.merge(ids, pair, idx)
self.merges[pair] = idx
# Update vocabulary
self.vocab[idx] = self.vocab[pair[0]] + self.vocab[pair[1]]
def encode(self, text: str) -> list:
"""
Encode text into tokens.
Args:
text (str): Text to encode.
Returns:
list: List of token IDs.
"""
if not self.vocab or not self.merges:
raise RuntimeError("Tokenizer must be trained first")
tokens = list(text.encode("utf-8"))
while len(tokens) >= 2:
stats = self.get_stats(tokens)
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
if pair not in self.merges:
break # Nothing else can be merged
idx = self.merges[pair]
tokens = self.merge(tokens, pair, idx)
return tokens
def decode(self, ids: list) -> str:
"""
Decode token IDs back into text.
Args:
ids (list): List of token IDs.
Returns:
str: Decoded text.
"""
if not self.vocab:
raise RuntimeError("Tokenizer must be trained first")
tokens = b"".join(self.vocab[idx] for idx in ids)
text = tokens.decode("utf-8", errors="replace")
return text
# Example usage
def main():
# Sample text for training
training_text = """
Hello world! This is a sample text to demonstrate BPE tokenization.
We'll use this to train our tokenizer and then test encoding and decoding.
"""
# Initialize and train tokenizer
tokenizer = BPETokenizer(vocab_size=512)
tokenizer.train(training_text)
# Test encoding and decoding
test_text = "Hello world!"
encoded = tokenizer.encode(test_text)
decoded = tokenizer.decode(encoded)
print(f"Original text: {test_text}")
print(f"Encoded tokens: {encoded}")
print(f"Decoded text: {decoded}")
print(f"Vocabulary size: {len(tokenizer.vocab)}")
if __name__ == "__main__":
main()What's Next
As discussed in the beginning tokenization is probably the most "problematically important" concept in NLP. A lot of problems in recent language models are because of the nature of tokenization. Here are some of the problems listed by Karpathy Sensei in his video:
- Why can't LLM spell words? Tokenization.
- Why can't LLM do super simple string processing tasks like reversing a string? Tokenization.
- Why is LLM worse at non-English languages (e.g. Japanese)? Tokenization.
- Why is LLM bad at simple arithmetic? Tokenization.
- Why is LLM not actually end-to-end language modeling? Tokenization.
- What is the real root of suffering? Tokenization.
Some of these problems have been solved by the newer version of LLMs however a lot of security and safety issue still exists. I would highly recommend anyone reading this blog to watch Karpathy Sensei's video on tokenization [1].
One of the major problem caused by tokenization is mathematical ability of larger language models [5, 6, 7, 8]. There have been several recent advancement in this direction that we will discuss in the next blog (hopefully 🙃)!!
References
- Andrej Karpathy's Tokenization Video
- SolidGoldMagikarp and Prompt Generation
- Hugging Face NLP Course - Tokenization
- Byte Pair Encoding - Wikipedia
- Number Tokenization Blog
- Tokenization and Mathematical Reasoning
- Right-to-Left Integer Tokenization
- Tokenization Effects on Language Models
- GPT-2 Paper
- Tokenization in Large Language Models
- Advanced Tokenization Techniques
- BPE vs Byte-level BPE
- Tiktokenizer
- Byte-level BPE Paper
- Oyoge! Taiyaki-kun