|
Mukul Ranjan I am a Master's student in Machine Learning at MBZUAI, where I work with Prof. Zhiqiang Shen. My research focuses on efficient machine learning systems, particularly developing alternate architectures and hardware-aware algorithms through sparsity, quantization, and hardware-software co-design. Most recently I also worked with Prof. Deming Chen at UIUC from Jul. 2025 to Oct. 2025. I also work on creating evaluation methodologies and benchmarks for these systems. Previously, I was a Data Scientist at Meesho, where I built personalized ranking systems, and an AI Research Scientist at Qure.ai, developing automated stroke severity assessment systems deployed in hospitals worldwide. I hold a B.Tech. in Electronics and Communication Engineering from IIT Guwahati. Email / CV / Scholar / Github / LinkedIn / X / Medium / Blogs / Poetry |

|
News
Feb 2026
NewTime-Blindness accepted at CVPR 2026!
Jan 2026
NewElastic-Cache accepted at ICLR 2026!
Jan 2026
NewMobile-MMLU accepted at DMLR 2026!
Oct 2025
Released Elastic-Cache, a training-free strategy that accelerates Diffusion LLMs up to 45.1x.
Jul 2025
Joined UIUC as a Research Scholar, working with Prof. Deming Chen on hybrid LLM inference.
May 2025
Released Time-Blindness! All VLMs score 0% on temporal patterns humans recognize at 98%.
Mar 2025
Released Mobile-MMLU, a 16K+ question benchmark for evaluating LLMs on mobile scenarios.
Feb 2025
KITAB-Bench accepted at ACL 2025!
Oct 2024
Won 1st place ($11,000) at the GITEX DGE Elite Hackathon for Cybersecurity.
Sep 2024
Won 1st place ($3,000) at the Insilico Medicine AI-driven Drug Discovery Hackathon.
Aug 2024
Started MS in Machine Learning at MBZUAI.
Feb 2022
Joined Meesho as a Data Scientist, building personalized ranking systems.
Dec 2021
Joined Qure.ai as an AI Research Scientist.
Jun 2021
Graduated from IIT Guwahati with B.Tech in ECE. Received Samsung Fellowship Award.
Mar 2021
Won Gold Medal at Inter-IIT Tech Meet for multilingual sentiment analysis.
|
PublicationsRepresentative papers are highlighted. * indicates equal contribution (random order). |
|
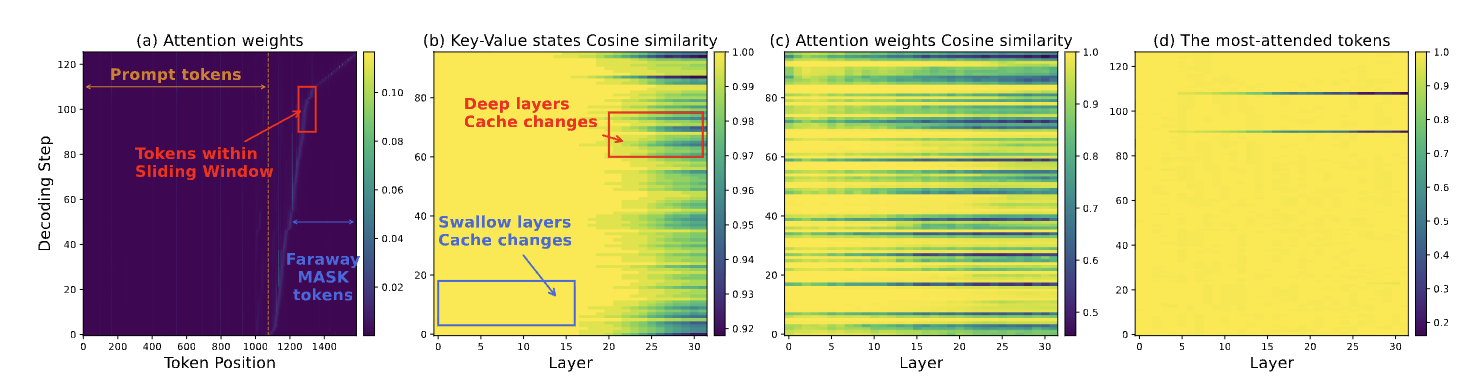
Attention Is All You Need for KV Cache in Diffusion LLMs
Mukul Ranjan*, Quan Nguyen-Tri*, and Zhiqiang Shen ICLR, 2026 arXiv / code / project page Elastic-Cache is a training-free framework that accelerates Diffusion LLMs up to 45.1x with higher accuracy by adaptively refreshing the KV cache. |
|
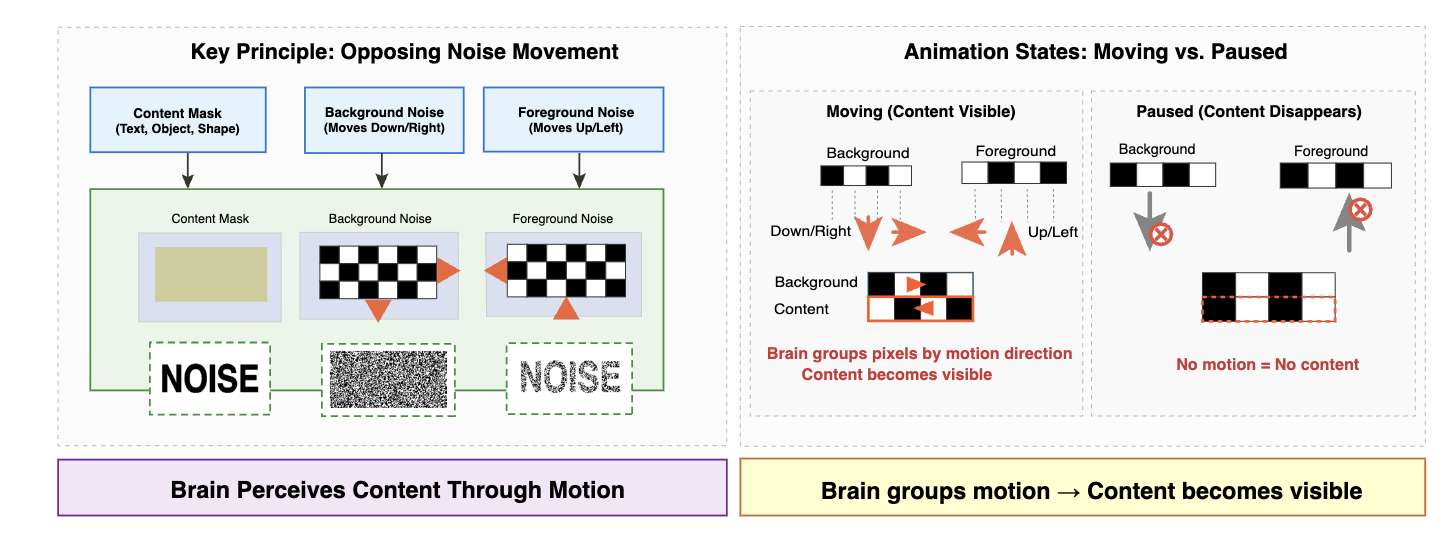
Time Blindness: Why Video-Language Models Can't See What Humans Can?
Mukul Ranjan*, Ujjwal Upadhyay*, Zhiqiang Shen, and Mohamed Elhoseiny CVPR, 2026 arXiv / code / project page SpookyBench reveals that patterns in temporal noise that humans recognize with 98% accuracy, state-of-the-art VLMs fails completely achieving 0%. |
|
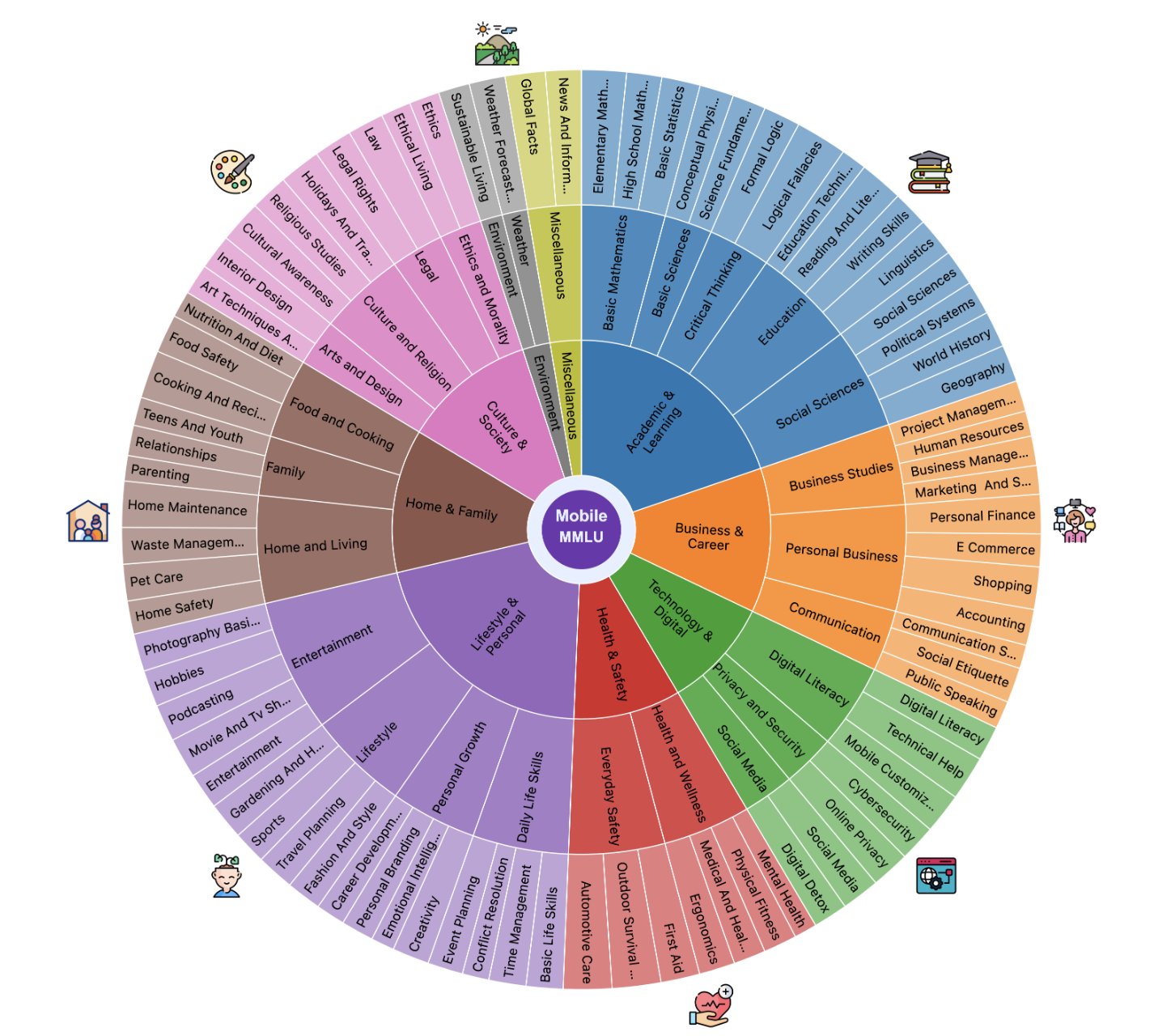
Mobile-MMLU: A Mobile Intelligence Language Understanding Benchmark
Mukul Ranjan*, Sondos Mahmoud Bsharat*, Aidar Myrzakhan*, et al. DMLR, 2026 arXiv / dataset / project page Mobile-MMLU is a benchmark with with 16,000+ questions across 80 mobile-related fields to evaluate LLM performance under real-world constraints. |
|
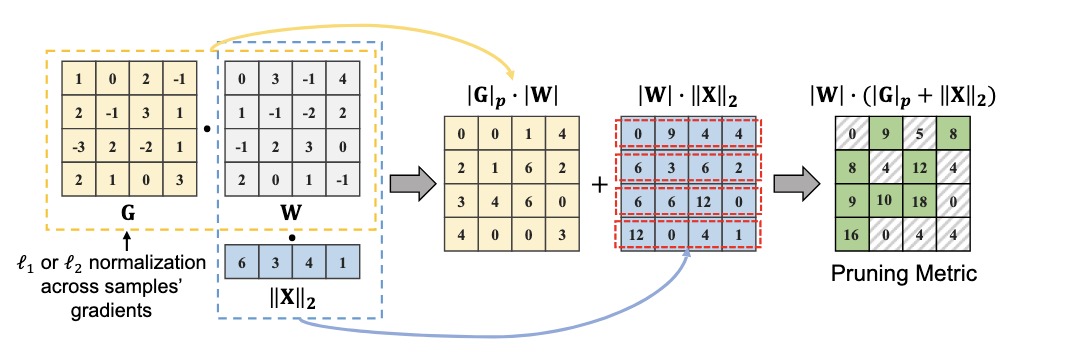
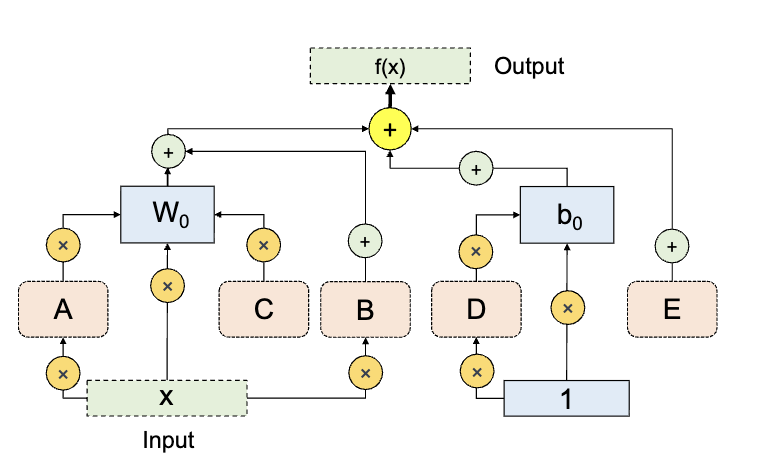
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Rocktim Jyoti Das*, Mukul Ranjan*, Mingjie Sun*, Liqun Ma, and Zhiqiang Shen Under Review arXiv (coming soon) / code GBLM-Pruner is a gradient-based pruning method that is extremeley faster than weight-update methods like SparseGPT. |
|
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
Arnav Chavan*, Mukul Ranjan*, Zhuang Liu, Deepak Gupta, Eric Xing, and Zhiqiang Shen Pending Submission for IEEE TPAMI, 2025 arXiv (coming soon) / code GLoRA is a unified PEFT framework achieving state-of-the-art accuracy with zero inference overhead through structural re-parameterization. |
|
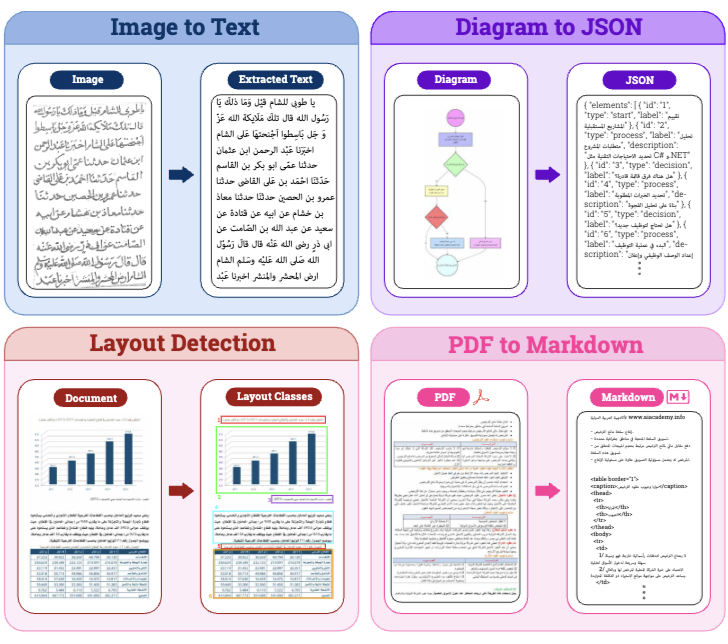
KITAB-Bench: A Comprehensive Multi-Domain Arabic OCR Benchmark
Mukul Ranjan*, Ahmed Heakl*, Muhammad Abdullah Sohail*, et al. ACL 2025 (Findings), 2025 arXiv / dataset KITAB-Bench has 8,809 samples across 9 domains. It reveals that vision-language models outperform traditional OCR by 60%. |
|
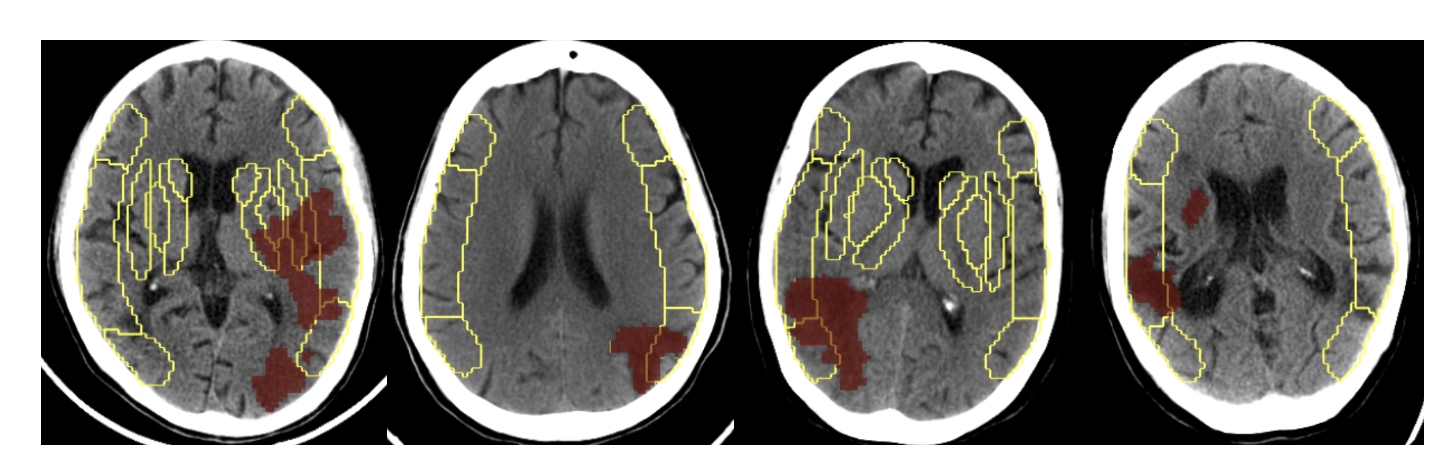
Deep-ASPECTS: A Segmentation-Assisted Model for Stroke Severity Measurement
Ujjwal Upadhyay, Mukul Ranjan, et al. ECCV, 2022 arXiv Deep-ASPECTS is an automated ASPECT scoring system achieving radiologist-level performance, now deployed in hospitals worldwide. |
|
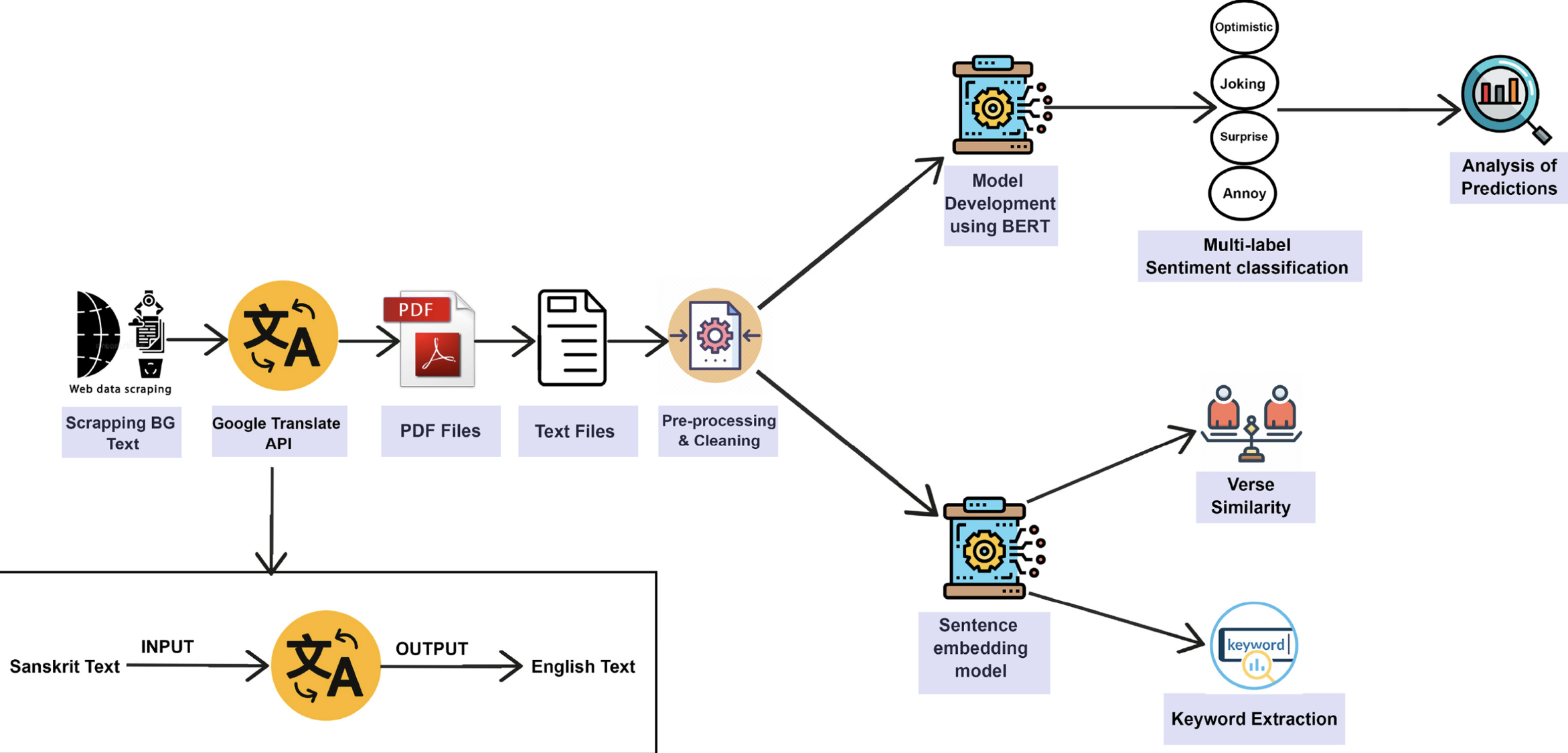
An Evaluation of Google Translate for Sanskrit to English Translation
Akshat Shukla, Chaarvi Bansal, Sushrut Badhe, Mukul Ranjan, and Rohitash Chandra Natural Language Processing Journal, 2023 paper |
|
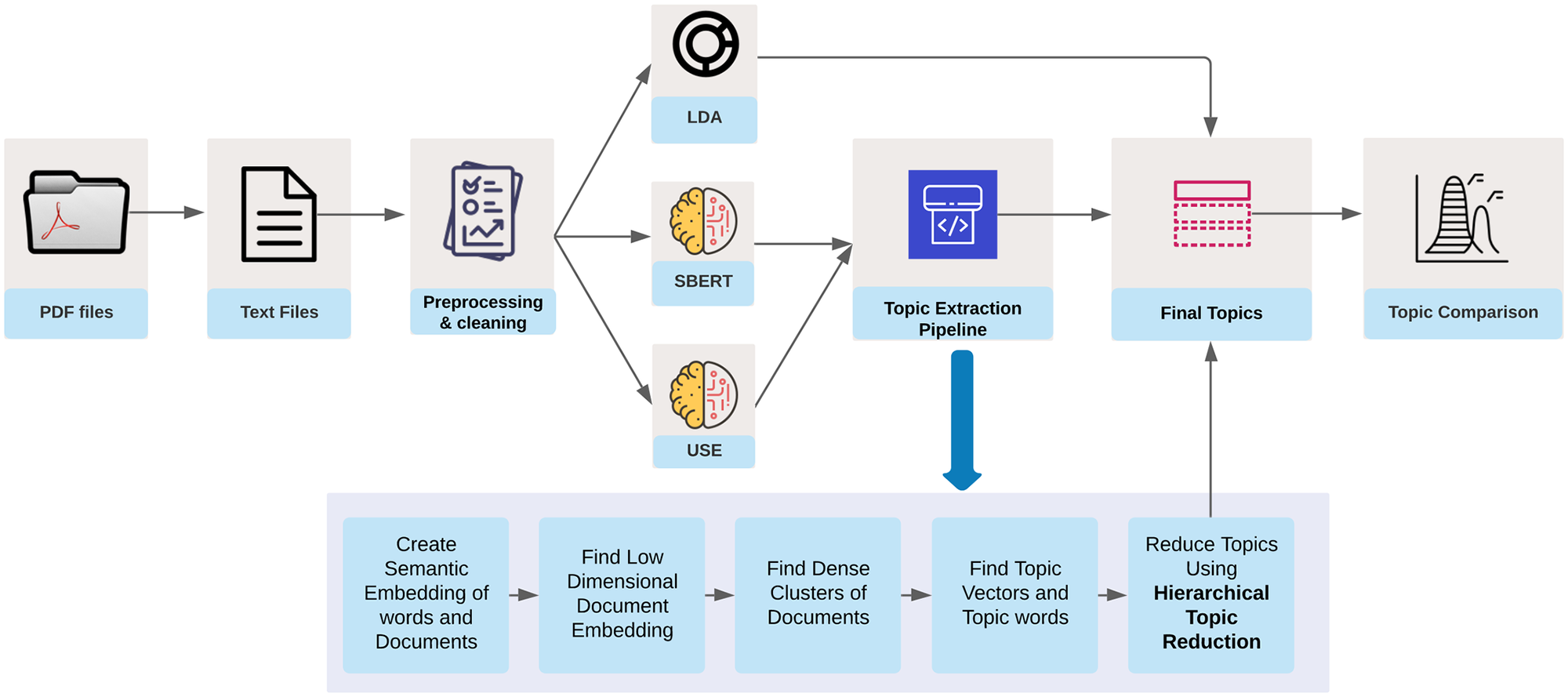
Artificial Intelligence for Topic Modelling in Hindu Philosophy
Mukul Ranjan* and Rohitash Chandra* PLOS ONE, 2022 paper |
|
Last updated: February 2026
|