Understanding HDFS Architecture
Exploring the Architecture and Functionality of HDFS: A Comprehensive Guide
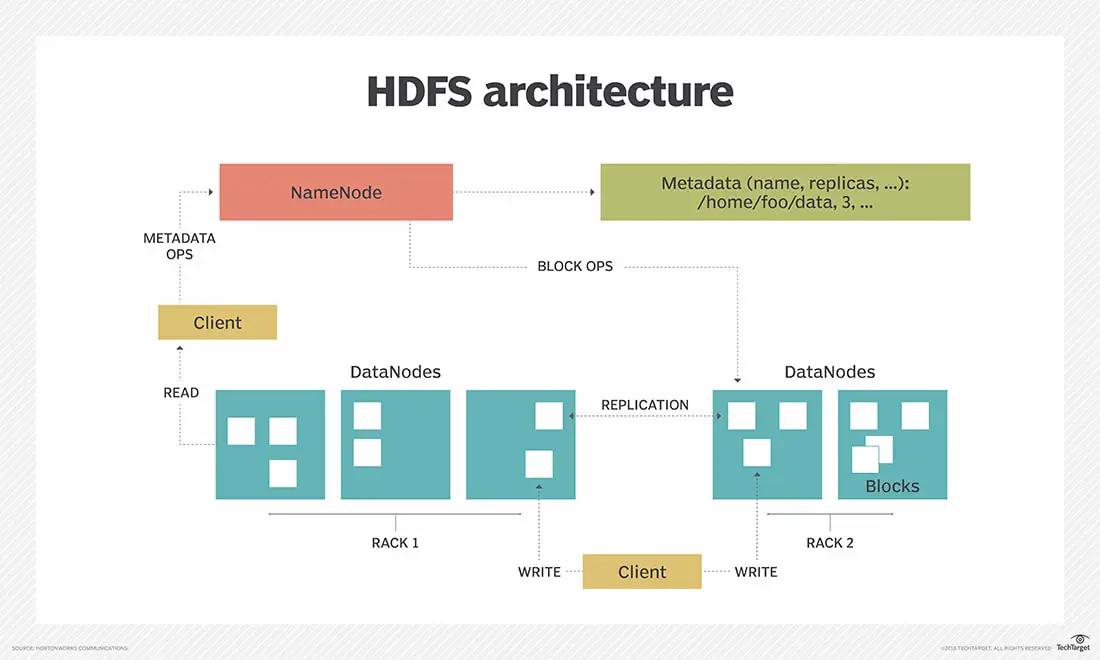 Image credit: Author
Image credit: Author
Hadoop Distributed File System(HDFS) is a distributed file system designed for handling and storing very large files running on clusters of commodity hardware. It is highly fault tolerant, designed to be deployed on low-cost, commodity hardware and It provides a very high throughput by providing parallel data access.
HDFS instance may consists of hundreds of server machines each storing part of file system data, hence failure of at least one server is inevitable. HDFS has been built to detect these failures and automatically recover them quickly.
HDFS follows master/slave architecture with **NameNode **as master and **DataNode **as slave. Each cluster comprises a single master node and multiple slave nodes. Internally the files get divided into one or more blocks, and each block is stored on different slave machines depending on the replication factor.
NameNode
-
It is the hardware that contains the operating system(GNU/Linux) and the NameNode software. It is responsible for serving the client’s read/write requests.
-
It Stores metadata such as number of blocks, their location, permission, replicas and other details on the local disk in the form of two files:
- FSImage(File System Image): It contains the complete namespace of the Hadoop file system since the NameNode creation.
- Edit log: It contains all the recent changes performed to the file system namespace to the most recent FSImage.
-
NameNode maintains and manages the slave nodes, and assigns tasks to them. It also keeps the status of data node and make sure that it is alive.
-
It can manage the files, control a client’s access to files, and overseas file operating processes such as renaming, opening, and closing files.
DataNode
-
For every node in the HDFS cluster we locate a DataNode which is hardware consisting operating system(GNU/Linux) and a DataNode software which help to control the data storage of their system as they can perform operations on the file systems if the client requests.
-
It can also create, replicate, and block files when the NameNode instructs.
-
Sends heartbeat and block report to the NameNode to report its health and the list of block it contains respectively.
Blocks
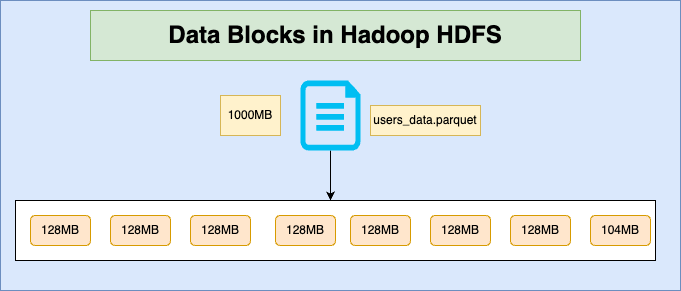
Internally HDFS split the file into multiple blocks with the default value of 128MB called block.
Rack
Rack is the collection of around 40–50 machines (DataNodes) connected using the same network switch. If the network goes down, the whole rack will be unavailable.
Rack Awareness in Hadoop is the concept that chooses DataNodes based on the rack information in the large Hadoop cluster, to improve the network traffic while reading/writing the HDFS file and to store replicas and provide latency and fault tolerance. For the default replication factor of 3, rank awareness algorithm will first store the replica on the local rack, while the second replica will get stored on DataNode in same rank and the third replica will get stored in different rack.
Understanding HDFS Read and Write Operation
Read Operation
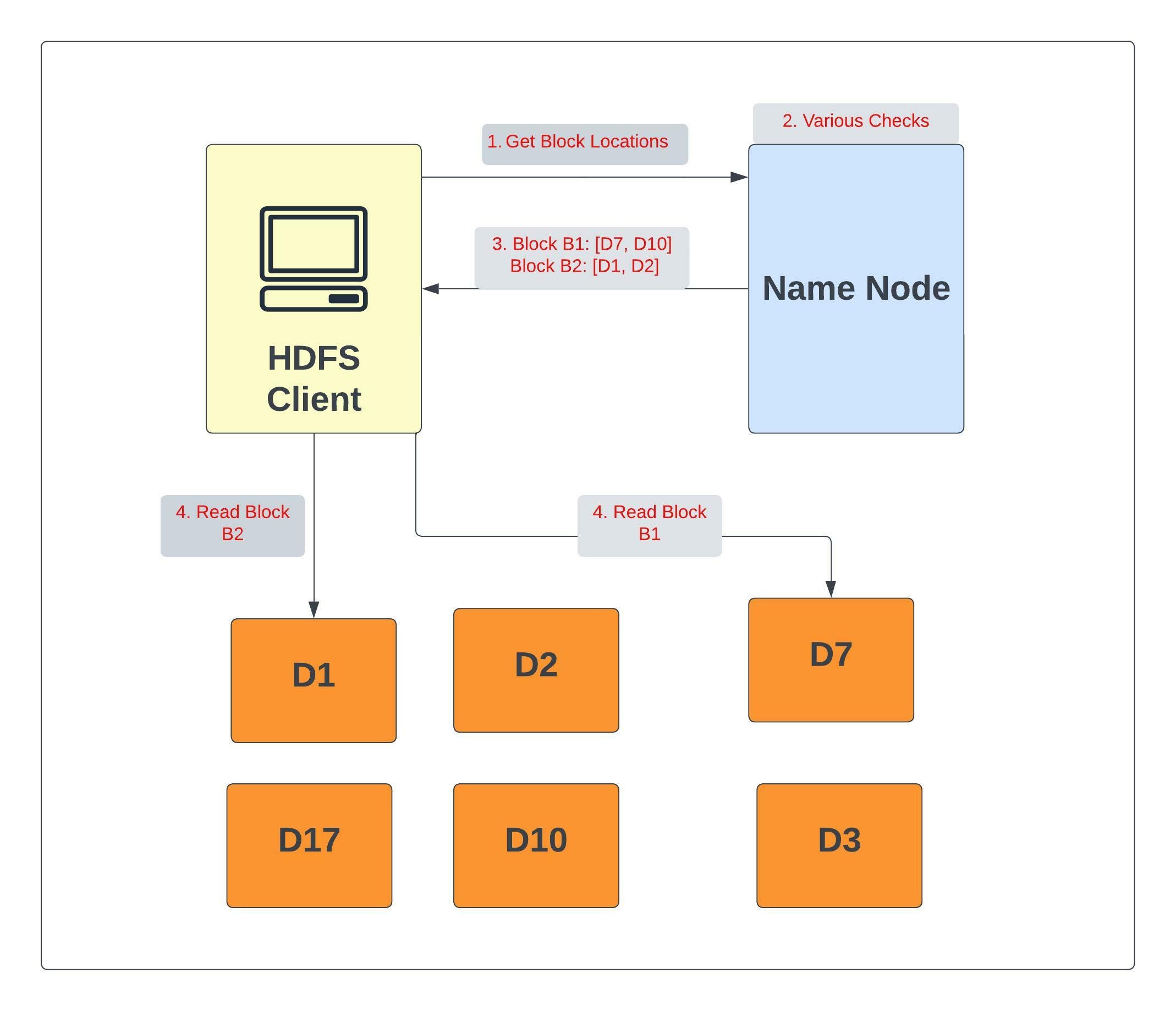
To read from HDFS, the client first communicates with the NameNode for metadata. The NameNode responds with the locations of DataNodes containing blocks. After receiving the DataNodes locations, the client then directly interacts with the DataNodes.
The client starts reading data in parallel from the DataNodes based on the information received from the NameNode. The data will flow directly from the DataNode to the client.
In the above image we can see that first client interact with Name Node to get the location of DataNode containing blocks B1 and B2. NameNode returns a list of DataNodes for each block. For Block B1 if DataNode D7 fails or data block is corrupted then next node in the list D10 will be picked up. Similarly for Block B2, if DataNode D1 fails or if data blocks are corrupted, then D2 will be picked up.
Failure Cases can be summarised as follows:
- Data block is corrupted:
- Next node in the list is picked up.
- Data Node fails:
- Next node in the list is picked up.
- That node is not tried for the later blocks.
When a client or application receives all the blocks of the file, it combines these blocks into the form of an original file.
Write Operation
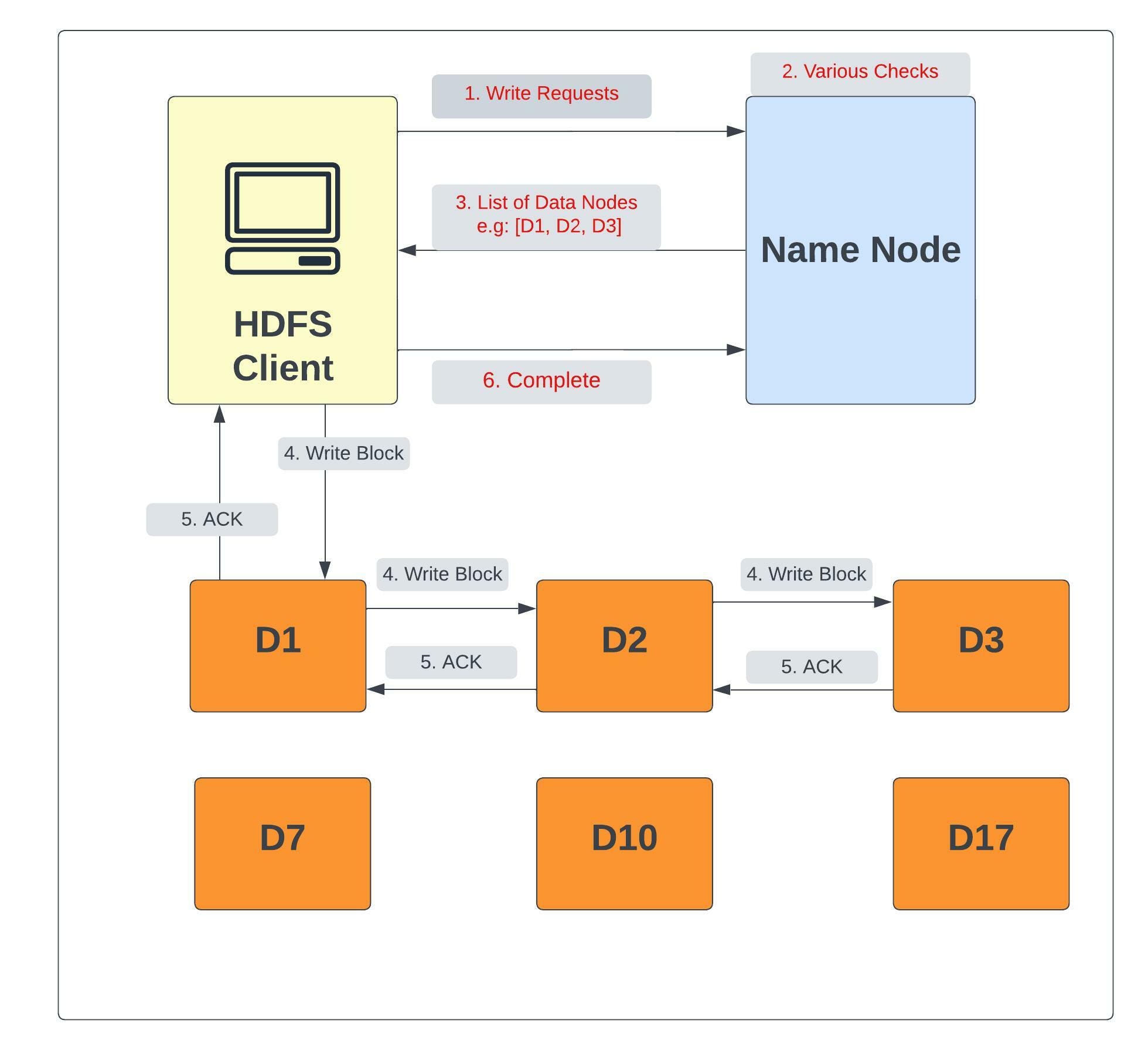
When a client wants to write a file to HDFS, it communicates to the NameNode for metadata. Name Node checks whether file is available or not as well as whether client is authorised or not (performs various checks) and then the NameNode responds with a number of blocks, their location, replicas, and other details. Based on information from NameNode, the client directly interacts with the DataNode.
In the above image we see that once client get the list of DataNode, it interact directly with them. Since the default replication factor for a block is 3, NameNode provides 3 DataNodes D1, D2 and D3 for the write request from the client. Data block is written and replicated in these 3 DataNodes and step 3, 4 and 5 will be repeated until whole file is written on HDFS. In case 1 of the Data Node fail, the data is written to the remaining 2 nodes and NameNode notices under-replication and arrange extra node for the replication. Once required replicas are created acknowledgement to the client is sent.
Before Hadoop2, NameNode was the single point of failure. The High Availability Hadoop cluster architecture introduced in Hadoop 2, allows for two or more NameNodes running in the cluster in a hot standby configuration.