How does Lasso regression(L1) encourage zero coefficients but not the L2?
We often read almost everywhere that Lasso regression **encourages zero coefficient, **and hence provide a great tool for variable selection as well but it is really difficult to get the intuition about this. In this article, I have tried to discuss this in detail.
Contents
-
Overfitting and Regularization
-
Intuition 1: Optimize a single coefficient model
-
Intuition 2: Look at this simple example
-
Intuition 3: Observe this beautiful image
-
Intuition 4: Probabilistic Interpretation of L1 and L2
Overfitting and Regularization
Overfitting is a phenomenon where a machine learning model is unable to generalize well on the unseen data. When our model is complex(for example polynomial regression with a very high degree or a very deep neural network) and we have less training data, in those cases model tends to memorize the training data and does not generalize well on unseen data.
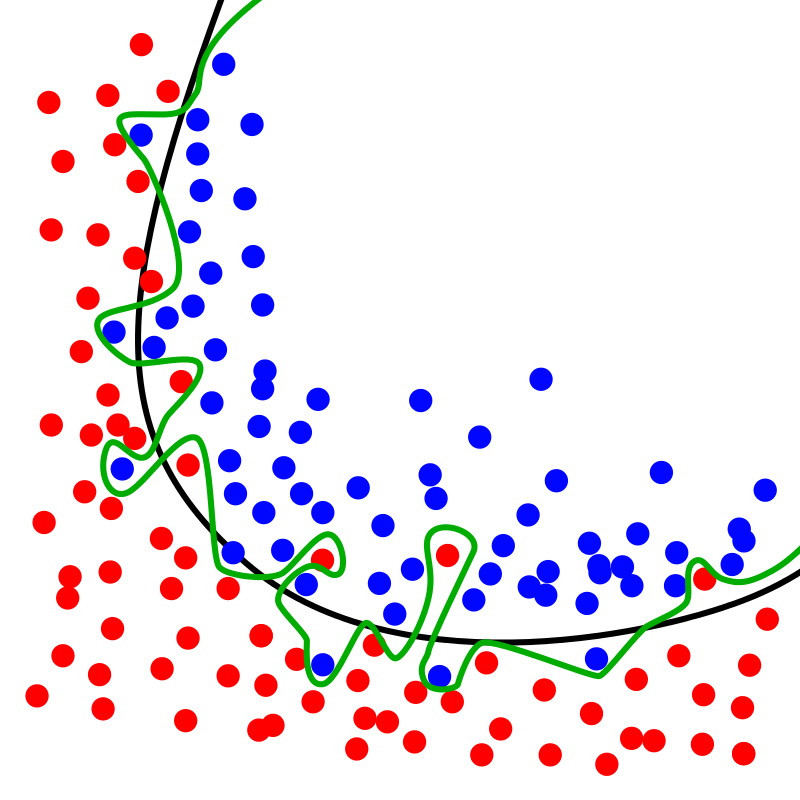
Look at this image from Wikipedia in which the green line shows the decision boundary of the overfitted classifier while the black one shows the regularized one. We see that even though the green decision boundary seems to give no training error it won’t generalize well on the unseen data.
Regularization is one of the ways to reduce the overfitting of a machine learning model by adding the extra penalty to the loss function. The penalty is added in terms of some norms of the parameters. When the loss function of the linear regression model uses the L1 norm of the parameters, the regression model is called Lasso Regression while the one which uses the L2 norms is called Ridge Regression.
Intuition 1: Optimize a single coefficient model
As explained here, consider a Ridge Regression model with a single coefficient β, the equation for the loss function of L2 regression in this can be given as follows:
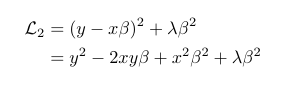
To minimize this equation, we will have to take the derivative w.r.t β and equate it to 0 to get the coefficient’s optimal value.
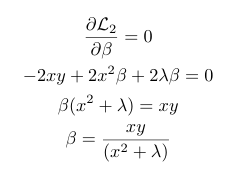
We see from the above equation that for coefficient β to be 0 for non-zero values of x and y, λ→∞. Now let’s look at the case for L1 or lasso regression.
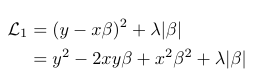
Consider the case where β>0, and minimize the expression for the L1 loss by differentiating it w.r.t β.
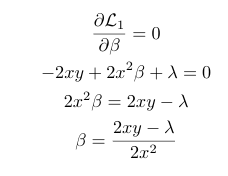
Similarly, for β<0, we get the following equation:
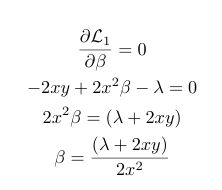
From both of the above equations, we see that in the case of L1 regularization, there are infinite possible values of x and y for a given *λ, *for which it is possible for β to be 0. Hence in contrast to Ridge regression, LASSO or L1 Regression encourages 0 coefficients therefore acting as a method of variable selection.
Intuition 2: Look at this simple example
This was the first good intuition that I found related to this topic in Murphy’s, Machine Learning: A Probabilistic Perspective (page no. 431). Consider a set of sparse vector β with two values, β₁ = (1, 0) and another set of dense vector β with two values such as β₂ = (1/√2, 1/√2).
In the case of L2 regularization, β₁ and β₂ both assign the same have weight since the L2 norm of both of them is the same.
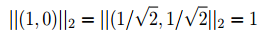
But when we look into the case of L1 regularization, if we look at the L1 norm of the β₁(the sparse vector), we find that it is less than that of β₂(the dense vector) as seen in the following equation.
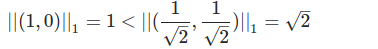
Hence, this shows that LASSO encourages zero coefficients.
Intuition 3: Observe this beautiful image
Here, we will look at the famous regularization diagram from Hastie’s ESL’s, page no 71.
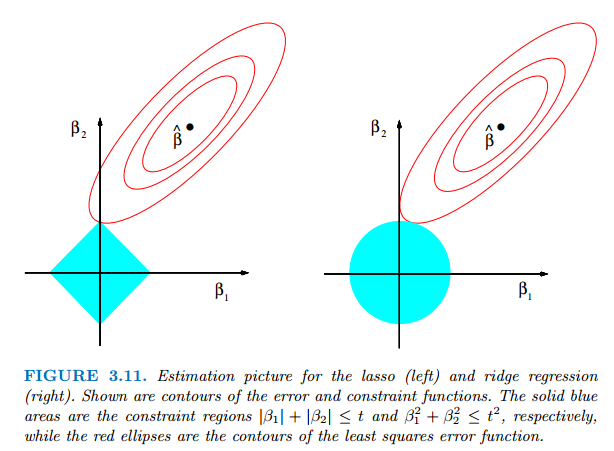
I had a really hard time understanding this figure until I came across this wonderful blog by explained.ai. I highly recommend you to look into that and various other blogs from the same author available at the site as well. They are really much more intuitive and well explained. You can find there the code for all the curves used by them as well.
Let’s look at the following two diagrams from the above-mentioned blogs.
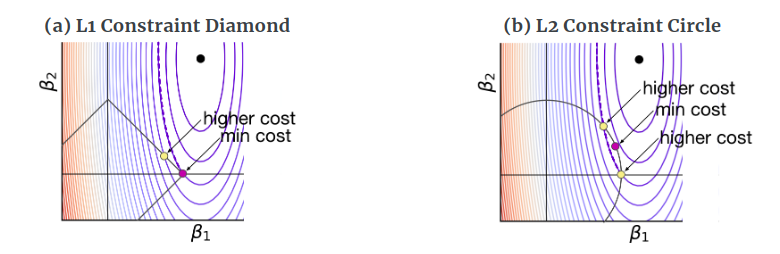
We see that the minimum cost in the case of the L1 is given by the purple dot at the diamond tip. As we move on the edge of the diamond, we find ourselves to be moving away from the **black dot **and hence there is a higher cost associated with it, for example, look at the yellow dot on the edge of the diamond. Hence in the case of L1 or LASSO regression, it is more likely to find the optimal parameter values at the tip of the diamond. In contrast to this, let’s look at the case of Ridge regression, i.e the L2 constrained circle; we see that the optimal value of parameters is not on the axis since we get the minimum cost at the purple dot, which is away from the axis. To be more clear, let’s look at another figure from the same blog.
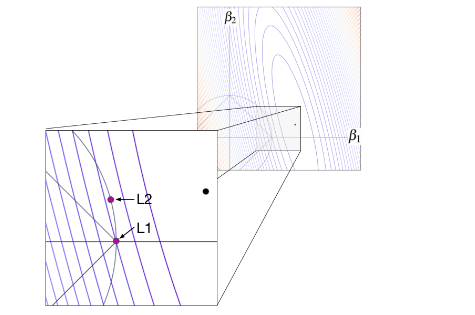
Intuition 4: Probabilistic Interpretation of L1 and L2
For this part, I assume that you know some basics of the Bayes Theorem. You can look into some of the resources related to it. I will skip a lot of details here. For more details, you can look into the answers to this cross-validated question and this wonderful blog by Brian Keng. Most of the equations and explanations here are from Brian Keng’s blog.
Maximum log-likelihood estimate for a linear regression model can be given by
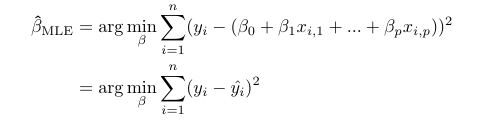
We simply choose that β for which mean squared error between the observed value y and predicted value ŷ is minimum. With a simple modification to the above expression, the maximum log-likelihood estimate for L1 and L2 regression can be written as follows:
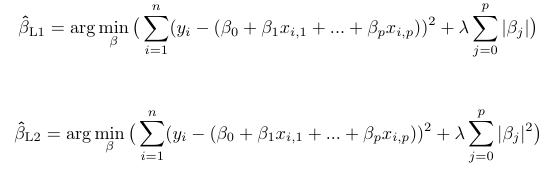
Likelihood estimate for ordinary linear regression can also be given by following(when we do not consider log) equation:
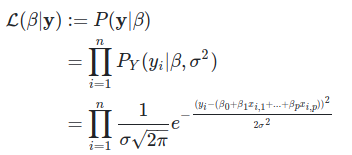
From Bayes Theorem we know that the posterior, is defined as follows:
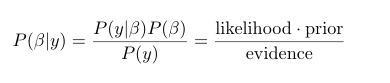
In case of Bayesian methods we are primarily concerned about the Posterior, i.e. the probability distribution of parameter β given the observed data y in contrast to the classical methods where we try to find the best parameters to maximize the likelihood i.e. the probability of observing data(y) given different value of parameters.
Priors are simply some additional previous information about β before coming across the data y.
The maximum a posteriori probability estimate(MAP)
In this case, we will try to maximize the P(β|y), i.e. the posterior probability. MAP is closely related to the MLE, but also includes prior distribution, therefore it acts as a regularization of MLE.
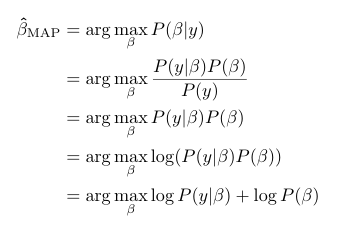
L2 Regularization and Gaussian Prior
Consider **a zero-mean normally distributed prior on each βᵢ value, all with identical variance τ². From the likelihood equation for Ordinary Linear Regression and the MAP estimate equation which we drive earlier, we have:
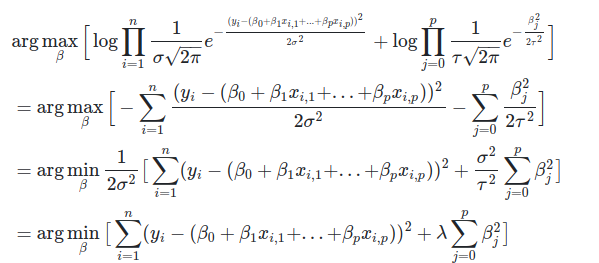
Thus, we see that the MAP estimate of Linear Regression coefficients with Gaussian priors gives us L2 or Ridge Regression.
Note that λ=σ²/τ² in the above equations. Also, remember that σ is assumed to be constant in linear regression, and we get to pick τ for our prior. We can adjust the amount of regularization we want, by changing λ.
L1 Regularization and Laplacian Prior
The probability distribution function for Laplace distribution is given by the following equation:
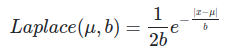
Considering the zero mean Laplacian priors on all the coefficients as we did in the previous section, we have:
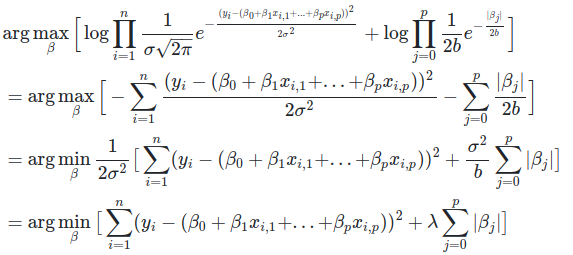
Again, we see that MAP of Linear Regression coefficients with Laplacian priors gives us L1 or Lasso Regression.
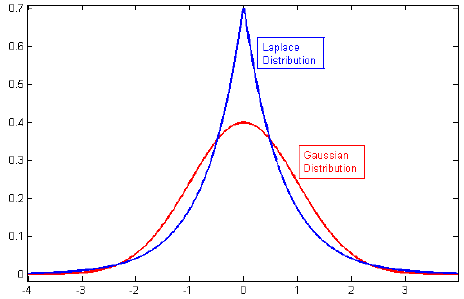
Look at the above graph for the Gaussian and Laplace distribution. As we discussed earlier that L1 or LASSO regression can be viewed as putting Laplace priors on the weights. Since the Laplace distribution is more concentrated around zero, our weight is more likely to be zero in the case of L1 or LASSO regularization.
Summary
-
L1 or LASSO(Least Absolute Shrinkage and Selection Operator) Regularization supports both variable selection and regularization simultaneously.
-
Both L1 and L2 regularization problems can be solved using the Lagrangian method of constrained optimization.
-
The lasso penalty will force some of the coefficients quickly to zero. This means that variables are removed from the model, hence the sparsity.
-
Ridge regression will more or less compress the coefficients to become smaller. This does not necessarily result in 0 coefficients and the removal of variables.
Reference
-
Hastie, Tibshirani and Friedman, The Elements of Statistical Learning
-
Machine Learning: A Probabilistic Perspective, Kevin P. Murphy
-
Why will ridge regression not shrink some coefficients to zero like lasso?
Mukul Ranjan
Data Scientist
My research interests include Reinforcement Learning, Recommender Systems, Representation Learning and Natural Language Processing.